Contacts vs distance
Welcome to the cooltools expected & contacts-vs-distance notebook!
In Hi-C maps, contact frequency decreases very strongly with genomic separation (also referred to as genomic distance). In the Hi-C field, this decay is often interchangeably referred to as the:
expected because one “expects” a certain average contact frequency at a given genomic separation
scaling which is borrowed from the polymer physics literature
P(s) curve contact probability, P, as a function of genomic separation, s.
The rate of decay of contacts with genomic separation reflects the polymeric nature of chromosomes and can tell us about the global folding patterns of the genome.
This decay has been observed to vary through the cell cycle, across cell types, and after degredation of structural maintenance of chromosomes complexes (SMCs) in both interphase and mitosis.
The goals of this notebook are to:
calculate the P(s) of a given cooler
plot the P(s) curve
smooth the P(s) curve with logarithmic binning
plot the derivative of P(s)
plot the P(s) between two different genomic regions
plot the matrix of average contact frequencies between different chromosomes
[1]:
%load_ext autoreload
%autoreload 2
[2]:
# import core packages
import warnings
warnings.filterwarnings("ignore")
from itertools import combinations
import os
# import semi-core packages
import matplotlib.pyplot as plt
from matplotlib import colors
%matplotlib inline
plt.style.use('seaborn-v0_8-poster')
import numpy as np
import pandas as pd
from multiprocessing import Pool
# import open2c libraries
import bioframe
import cooler
import cooltools
from packaging import version
if version.parse(cooltools.__version__) < version.parse('0.5.2'):
raise AssertionError("tutorial relies on cooltools version 0.5.2 or higher,"+
"please check your cooltools version and update to the latest")
# count cpus
num_cpus = os.getenv('SLURM_CPUS_PER_TASK')
if not num_cpus:
num_cpus = os.cpu_count()
num_cpus = int(num_cpus)
[3]:
# download test data
# this file is 145 Mb, and may take a few seconds to download
cool_file = cooltools.download_data("HFF_MicroC", cache=True, data_dir='./data/')
print(cool_file)
./data/test.mcool
[4]:
# Load a Hi-C map at a 1kb resolution from a cooler file.
resolution = 1000 # note this might be slightly slow on a laptop
# and could be lowered to 10kb for increased speed
clr = cooler.Cooler('data/test.mcool::/resolutions/'+str(resolution))
In addition to data stored in a cooler, the analyses below make use of where chromosomal arms start and stop to calculate contact frequency versus distance curves within arms. For commonly-used genomes, bioframe can be used to fetch these annotations directly from UCSC. For less commonly-used genomes, a table of arms, or chromosomes can be loaded in directly with pandas, e.g.
chromsizes = pd.read_csv('chrom.sizes', sep='\t')
Regions for calculating expected should be provided as a viewFrame, i.e. a dataframe with four columns, chrom, start, stop, name, where entries in the name column are unique and the intervals are non-overlapping. If the chromsizes table does not have a name column, it can be created with bioframe.core.construction.add_ucsc_name_column(bioframe.make_viewframe(chromsizes)).
[5]:
# Use bioframe to fetch the genomic features from the UCSC.
hg38_chromsizes = bioframe.fetch_chromsizes('hg38')
hg38_cens = bioframe.fetch_centromeres('hg38')
# create a view with chromosome arms using chromosome sizes and definition of centromeres
hg38_arms = bioframe.make_chromarms(hg38_chromsizes, hg38_cens)
# select only those chromosomes available in cooler
hg38_arms = hg38_arms[hg38_arms.chrom.isin(clr.chromnames)].reset_index(drop=True)
hg38_arms
[5]:
| chrom | start | end | name | |
|---|---|---|---|---|
| 0 | chr2 | 0 | 93900000 | chr2_p |
| 1 | chr2 | 93900000 | 242193529 | chr2_q |
| 2 | chr17 | 0 | 25100000 | chr17_p |
| 3 | chr17 | 25100000 | 83257441 | chr17_q |
Calculate the P(s) curve
To calculate the average contact frequency as a function of genomic separation, we use the fact that each diagonal of a Hi-C map records contacts between loci separated by the same genomic distance. For example, the 3rd diagonal of our matrix contains contacts between loci separated by 3-4kb (note that diagonals are 0-indexed). Thus, we calculate the average contact frequency, P(s), at a given genomic distance, s, as the average value of all pixels of the corresponding diagonal. This
operation is performed by cooltools.expected_cis.
Note that we calculate the P(s) separately for each chromosomal arm, by providing hg38_arms as a view_df. This way we will ignore contacts accross the centromere, which is generally a good idea, since such contacts have a slightly different decay versus genomic separation.
[6]:
# cvd == contacts-vs-distance
cvd = cooltools.expected_cis(
clr=clr,
view_df=hg38_arms,
smooth=False,
aggregate_smoothed=False,
nproc=num_cpus #if you do not have multiple cores available, set to 1
)
INFO:root:creating a Pool of 10 workers
This function calculates average contact frequency for raw and normalized interactions ( count.avg and balanced.avg) for each diagonal and each regions in the hg38_arms of a Hi-C map. It aslo keeps the sum of raw and normalized interaction counts (count.sum and balanced.sum) as well as the number of valid (i.e. non-masked) pixels at each diagonal, n_valid.
[7]:
display(cvd.head(4))
display(cvd.tail(4))
| region1 | region2 | dist | dist_bp | contact_frequency | n_total | n_valid | count.sum | balanced.sum | count.avg | balanced.avg | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chr2_p | chr2_p | 0 | 0 | NaN | 93900 | 86055 | NaN | NaN | NaN | NaN |
| 1 | chr2_p | chr2_p | 1 | 1000 | NaN | 93899 | 85282 | NaN | NaN | NaN | NaN |
| 2 | chr2_p | chr2_p | 2 | 2000 | 0.098270 | 93898 | 84918 | 10842540.0 | 8344.916674 | 115.471469 | 0.098270 |
| 3 | chr2_p | chr2_p | 3 | 3000 | 0.042805 | 93897 | 84649 | 4733321.0 | 3623.417357 | 50.409715 | 0.042805 |
| region1 | region2 | dist | dist_bp | contact_frequency | n_total | n_valid | count.sum | balanced.sum | count.avg | balanced.avg | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 325448 | chr17_q | chr17_q | 58154 | 58154000 | NaN | 4 | 0 | 0.0 | 0.0 | 0.0 | NaN |
| 325449 | chr17_q | chr17_q | 58155 | 58155000 | NaN | 3 | 0 | 0.0 | 0.0 | 0.0 | NaN |
| 325450 | chr17_q | chr17_q | 58156 | 58156000 | NaN | 2 | 0 | 0.0 | 0.0 | 0.0 | NaN |
| 325451 | chr17_q | chr17_q | 58157 | 58157000 | NaN | 1 | 0 | 0.0 | 0.0 | 0.0 | NaN |
Note that the data from the first couple of diagonals are masked. This is done intentionally, since interactions at these diagonals (very short-ranged) are contaminated by non-informative Hi-C byproducts - dangling ends and self-circles.
Plot the P(s) curve
Time to plot P(s) !
The first challenge is that Hi-C has a very wide dynamic range. Hi-C probes genomic separations ranging from 100s to 100,000,000s of basepairs and contact frequencies also tend to span many orders of magnitude.
Plotting such data in the linear scale would reveal only a part of the whole picture. Instead, we typically switch to double logarithmic (aka log-log) plots, where the x and y coordinates vary by orders of magnitude.
With the flags used above, expected_cis() does not smooth or aggregate across regions. This can lead to noisy P(s) curves for each region:
[8]:
f, ax = plt.subplots(1,1)
for region in hg38_arms['name']:
ax.loglog(
cvd['dist_bp'].loc[cvd['region1']==region],
cvd['contact_frequency'].loc[cvd['region1']==region],
)
ax.set(
xlabel='separation, bp',
ylabel='IC contact frequency')
ax.set_aspect(1.0)
ax.grid(lw=0.5)
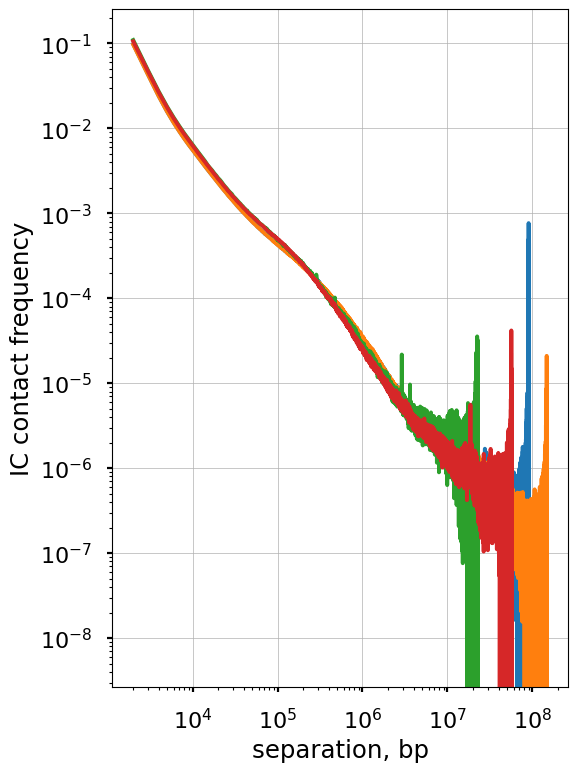
The non-smoothed curves plotted above form characteristic “fans” at longer separations. This happens for two reasons: (a) we plot values of each diagonal separately and thus each decade of s contains 10x more points, and (b) due to the polymer nature of chromosomes, contact frequency at large genomic separations are lower and thus more affected by sequencing depth.
This issue is more that just cosmetic, as this noise would prevent us from doing finer analyses of P(s) and propagate into data derived from P(s). However, there is a simple solution: we can smooth P(s) over multiple diagonals. This works because P(s) changes very gradually with s, so that consecutive diagonals have similar values. Furthermore, we can make each subsequent smoothing window wider than the previous one, so that each order of magnitude of genomic separation contains the
same number of windows. Such aggregation is a little tricky to perform, so cooltools.expected implements this operation.
Smoothing & aggregating P(s) curves
Instead of the flags above, we can pass flags to expected_cis() that return smoothed and aggregated columns for futher analysis (which are on by default).
Note that the plots below use smooth_sigma=0.1, which is relatively conservative, and this parameter can be lowered (with discretion) for sufficiently high-resolution datasets.
[9]:
cvd_smooth_agg = cooltools.expected_cis(
clr=clr,
view_df=hg38_arms,
smooth=True,
aggregate_smoothed=True,
smooth_sigma=0.1,
nproc=num_cpus
)
INFO:root:creating a Pool of 10 workers
[10]:
display(cvd_smooth_agg.head(4))
| region1 | region2 | dist | dist_bp | contact_frequency | n_total | n_valid | count.sum | balanced.sum | count.avg | balanced.avg | balanced.avg.smoothed | balanced.avg.smoothed.agg | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chr2_p | chr2_p | 0 | 0 | NaN | 93900 | 86055 | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | chr2_p | chr2_p | 1 | 1000 | 0.001060 | 93899 | 85282 | NaN | NaN | NaN | NaN | 0.001043 | 0.001060 |
| 2 | chr2_p | chr2_p | 2 | 2000 | 0.088615 | 93898 | 84918 | 10842540.0 | 8344.916674 | 115.471469 | 0.098270 | 0.087228 | 0.088615 |
| 3 | chr2_p | chr2_p | 3 | 3000 | 0.043947 | 93897 | 84649 | 4733321.0 | 3623.417357 | 50.409715 | 0.042805 | 0.043116 | 0.043947 |
[11]:
cvd_smooth_agg['balanced.avg.smoothed'].loc[cvd_smooth_agg['dist'] < 2] = np.nan
f, ax = plt.subplots(1,1)
for region in hg38_arms['name']:
ax.loglog(
cvd_smooth_agg['dist_bp'].loc[cvd_smooth_agg['region1']==region],
cvd_smooth_agg['balanced.avg.smoothed'].loc[cvd_smooth_agg['region1']==region],
)
ax.set(
xlabel='separation, bp',
ylabel='IC contact frequency')
ax.set_aspect(1.0)
ax.grid(lw=0.5)
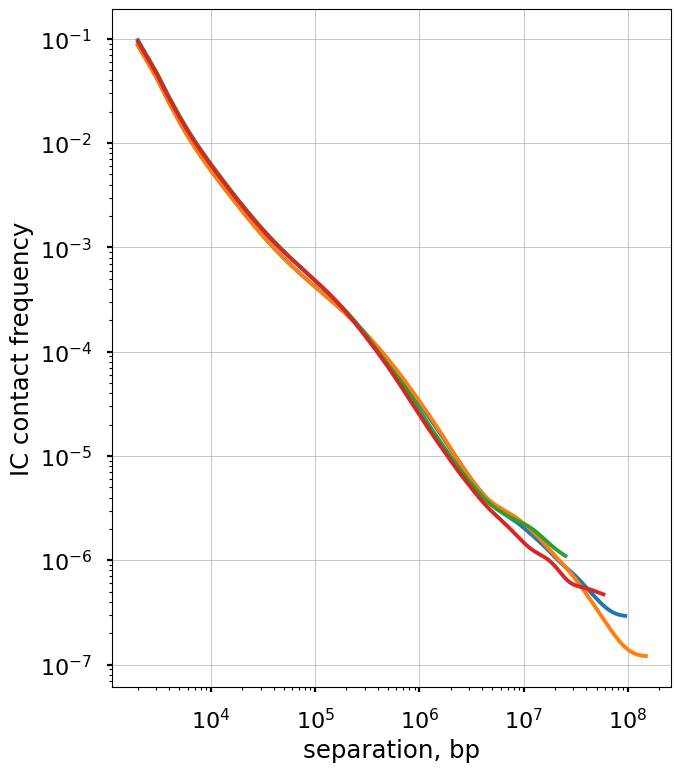
The balanced.avg.smoothed.agg is averaged across regions, and shows the same exact curve for each.
[12]:
cvd_smooth_agg['balanced.avg.smoothed.agg'].loc[cvd_smooth_agg['dist'] < 2] = np.nan
f, ax = plt.subplots(1,1)
for region in hg38_arms['name']:
ax.loglog(
cvd_smooth_agg['dist_bp'].loc[cvd_smooth_agg['region1']==region],
cvd_smooth_agg['balanced.avg.smoothed.agg'].loc[cvd_smooth_agg['region1']==region],
)
ax.set(
xlabel='separation, bp',
ylabel='IC contact frequency')
ax.set_aspect(1.0)
ax.grid(lw=0.5)
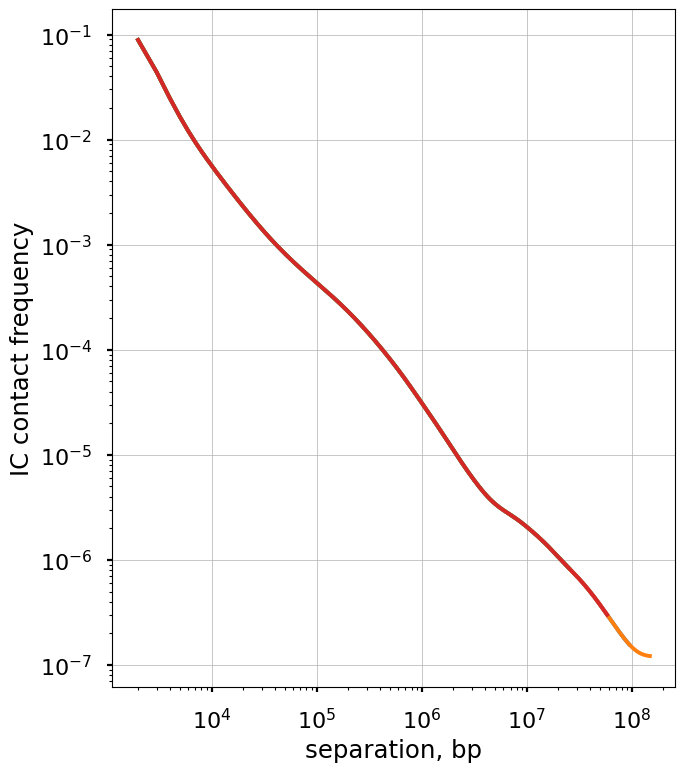
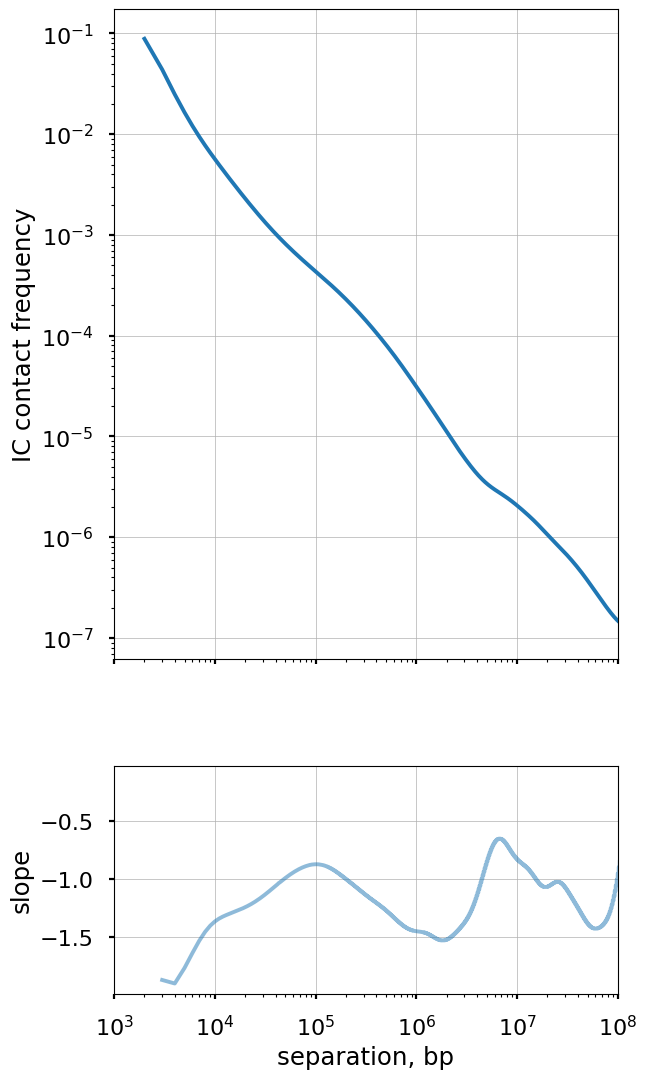
Plot the smoothed P(s) curve and its derivative
Logbin-smoothing of P(s) reduces the “fanning” at longer s and enables us to plot the derivative of the P(s) curve in the log-log space. This derivative is extremely informative, as it can be compared to predictions from various polymer models.
[13]:
# Just take a single value for each genomic separation
cvd_merged = cvd_smooth_agg.drop_duplicates(subset=['dist'])[['dist_bp', 'balanced.avg.smoothed.agg']]
[14]:
# Calculate derivative in log-log space
der = np.gradient(np.log(cvd_merged['balanced.avg.smoothed.agg']),
np.log(cvd_merged['dist_bp']))
[15]:
f, axs = plt.subplots(
figsize=(6.5,13),
nrows=2,
gridspec_kw={'height_ratios':[6,2]},
sharex=True)
ax = axs[0]
ax.loglog(
cvd_merged['dist_bp'],
cvd_merged['balanced.avg.smoothed.agg'],
'-'
)
ax.set(
ylabel='IC contact frequency',
xlim=(1e3,1e8)
)
ax.set_aspect(1.0)
ax.grid(lw=0.5)
ax = axs[1]
ax.semilogx(
cvd_merged['dist_bp'],
der,
alpha=0.5
)
ax.set(
xlabel='separation, bp',
ylabel='slope')
ax.grid(lw=0.5)
Plot the P(s) curve for interactions between different regions.
Finally, we can plot P(s) curves for contacts between loci that belong to different regions.
A commonly considered situation is for trans-arm interactions, i.e. contacts between loci on the opposite side of a centromere. Such P(s) can be calculated via cooltools.expected_cis by passing intra_only=False.
[16]:
# cvd_inter == contacts-vs-distance between chromosomal arms
cvd_inter = cooltools.expected_cis(
clr=clr,
view_df=hg38_arms,
intra_only=False,
nproc=num_cpus
)
# select only inter-arm interactions:
cvd_inter = cvd_inter[ cvd_inter["region1"] != cvd_inter["region2"] ].reset_index(drop=True)
INFO:root:creating a Pool of 10 workers
[17]:
cvd_inter['balanced.avg.smoothed.agg'].loc[cvd_inter['dist'] < 2] = np.nan
f, ax = plt.subplots(1,1,
figsize=(5,5),)
ax.loglog(
cvd_inter['dist_bp'],
cvd_inter['balanced.avg.smoothed.agg'],
)
ax.set(
xlabel='separation, bp',
ylabel='IC contact frequency',
title="average interactions between chromosomal arms")
ax.grid(lw=0.5)
ax.set_aspect(1.0)
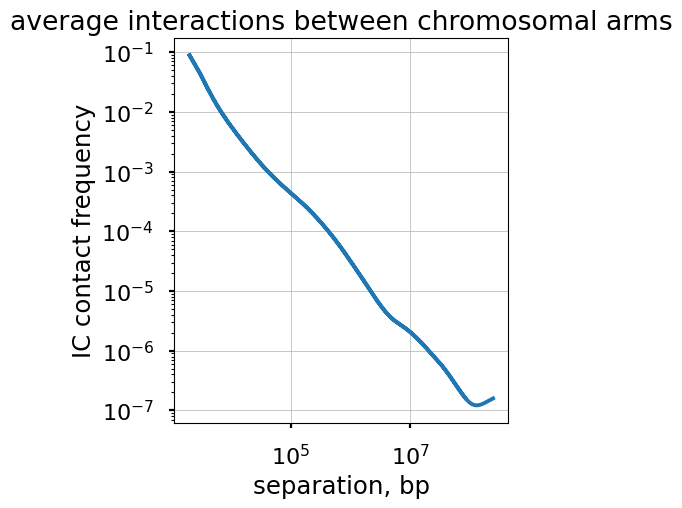
Averaging interaction frequencies in blocks
For trans (i.e. inter-chromosomal) interactions, the notion of “genomic separation” becomes irrelevant, as loci on different chromosomes are not connected by any polymer chain. Thus, the “expected” level of trans interactions is a scalar, the average interaction frequency for a given pair of chromosomes.
Note that this sample dataset only includes two chromosomes– the heatmap of pairwise average contact frequencies can appear much more interesting for a greater number of chromosomes.
[18]:
# average contacts, in this case between pairs of chromosomal arms:
ac = cooltools.expected_trans(
clr,
view_df = None, # full chromosomes as the view
nproc=num_cpus
)
# average raw interaction counts and normalized contact frequencies are already in the result
ac
INFO:root:creating a Pool of 10 workers
[18]:
| region1 | region2 | n_valid | count.sum | balanced.sum | count.avg | balanced.avg | |
|---|---|---|---|---|---|---|---|
| 0 | chr2 | chr17 | 16604223614 | 1307071.0 | 1021.728671 | 0.000079 | 6.153426e-08 |
[19]:
# pivot a table to generate a pair-wise average interaction heatmap:
acp = (ac
.pivot_table(values="balanced.avg",
index="region1",
columns="region2",
observed=True)
.reindex(index=clr.chromnames,
columns=clr.chromnames)
)
[20]:
fs = 14
f, axs = plt.subplots(
figsize=(6.0,5.5),
ncols=2,
gridspec_kw={'width_ratios':[20,1],"wspace":0.1},
)
# assign heatmap and colobar axis:
ax, cax = axs
# draw a heatmap, using log-scale for interaction freq-s:
acpm = ax.imshow(
acp,
cmap="YlOrRd",
norm=colors.LogNorm(),
aspect=1.0
)
# assign ticks and labels (ordered names of chromosome arms):
ax.set(
xticks=range(len(clr.chromnames)),
yticks=range(len(clr.chromnames)),
title="average interactions\nbetween chromosomes",
)
ax.set_xticklabels(
clr.chromnames,
rotation=30,
horizontalalignment='right',
fontsize=fs
)
ax.set_yticklabels(
clr.chromnames,
fontsize=fs
)
# draw a colorbar of interaction frequencies for the heatmap:
f.colorbar(
acpm,
cax=cax,
label='IC contact frequency'
)
# draw a grid around values:
ax.set_xticks(
[x-0.5 for x in range(1,len(clr.chromnames))],
minor=True
)
ax.set_yticks(
[y-0.5 for y in range(1,len(clr.chromnames))],
minor=True
)
ax.grid(which="minor")
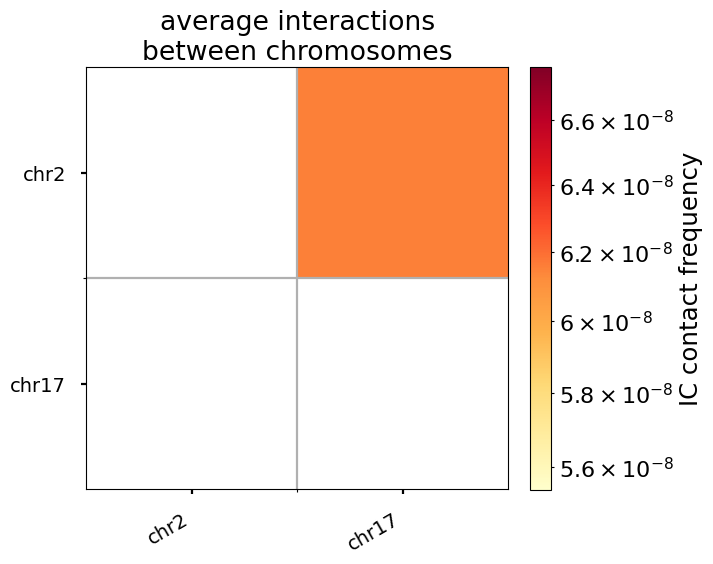
Impact of sequencing depth on computed P(s)
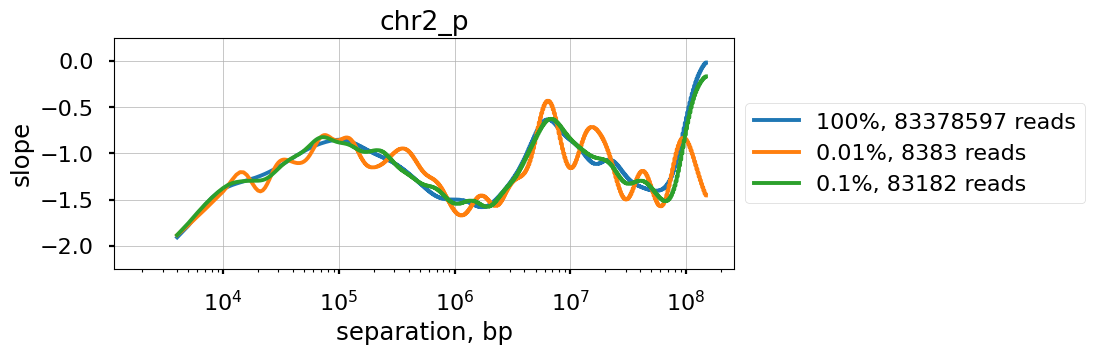
We explore the influence of sequencing coverage on calculating P(s) curves using cooltools.sample() to generate downsampled coolers from the Kreitenstein microC test dataset. We then compute raw P(s) and smoothed P(s) at various levels of downsampling, for the q arm of chr2.
Raw P(s) appear very noisy even with 0.1% downsampling. Smoothed P(s) are fairly consistent down to 0.01% downsampling. Derivatives, however, are less reliable at 0.01% downsampling.
[31]:
# create downsampled test data
downsampling_fracs = [0.0001, 0.001]
num_reads = {}
cvds = {}
cvds_smoothed = {}
derivs_smoothed = {}
p = Pool(num_cpus)
for frac in downsampling_fracs:
cooltools.sample(clr, out_clr_path=f'./data/test_sampled_{frac}_.cool', frac=frac, nproc=num_cpus)
clr_downsampled = cooler.Cooler(f'./data/test_sampled_{frac}_.cool')
result = cooler.balance_cooler(clr_downsampled, map=p.map, store=True, min_nnz=0)
p.close()
p.terminate()
INFO:root:creating a Pool of 10 workers
INFO:root:creating a Pool of 10 workers
[32]:
# expected & derivative calculation for raw data, using only the second arm of chr2
cvd_smooth_agg_raw = cooltools.expected_cis(
clr=clr,
view_df=hg38_arms[1:2],
clr_weight_name=None,
smooth=True,
aggregate_smoothed=True,
nproc=num_cpus
)
cvd_smooth_agg_raw['count.avg.smoothed'].loc[cvd_smooth_agg_raw['dist'] < 2] = np.nan
cvd_merged = cvd_smooth_agg_raw.drop_duplicates(subset=['dist'])[['dist_bp', 'count.avg.smoothed.agg']]
der = np.gradient(np.log(cvd_merged['count.avg.smoothed.agg']),
np.log(cvd_merged['dist_bp']))
deriv_smoothed_raw = der
cvds[1.0] = cvd_smooth_agg_raw.copy()
cvds_smoothed[1.0]= cvd_smooth_agg_raw.copy()
num_reads[1.0] = cvd_smooth_agg_raw['count.sum'].sum().astype(int)
derivs_smoothed[1.0] = deriv_smoothed_raw
INFO:root:creating a Pool of 10 workers
[39]:
# expected calculation for the downsampled data
for frac in downsampling_fracs:
clr_downsampled = cooler.Cooler(f'./data/test_sampled_{frac}_.cool')
cvd_downsampled = cooltools.expected_cis(
clr=clr_downsampled,
view_df=hg38_arms[1:2],
clr_weight_name=None,
smooth=False,
aggregate_smoothed=False,
nproc=num_cpus #if you do not have multiple cores available, set to 1
)
cvds[frac] = cvd_downsampled
num_reads[frac] = cvd_downsampled['count.sum'].sum().astype(int)
INFO:root:creating a Pool of 10 workers
INFO:root:creating a Pool of 10 workers
[42]:
f, ax = plt.subplots(1,1, figsize=(8, 8))
region = hg38_arms['name'][0]
for frac in [1]+downsampling_fracs:
cvd_downsampled = cvds[frac]
ax.loglog(
cvd_downsampled['dist_bp'],
cvd_downsampled['count.avg'],
label=f'{frac*100}%, {num_reads[frac]} reads',
)
ax.set(
xlabel='separation, bp',
ylabel='contact frequency')
ax.grid(lw=0.5)
ax.legend()
ax.title.set_text(region)
ax.set_ylim(ymin=10**(-8))
f.show()
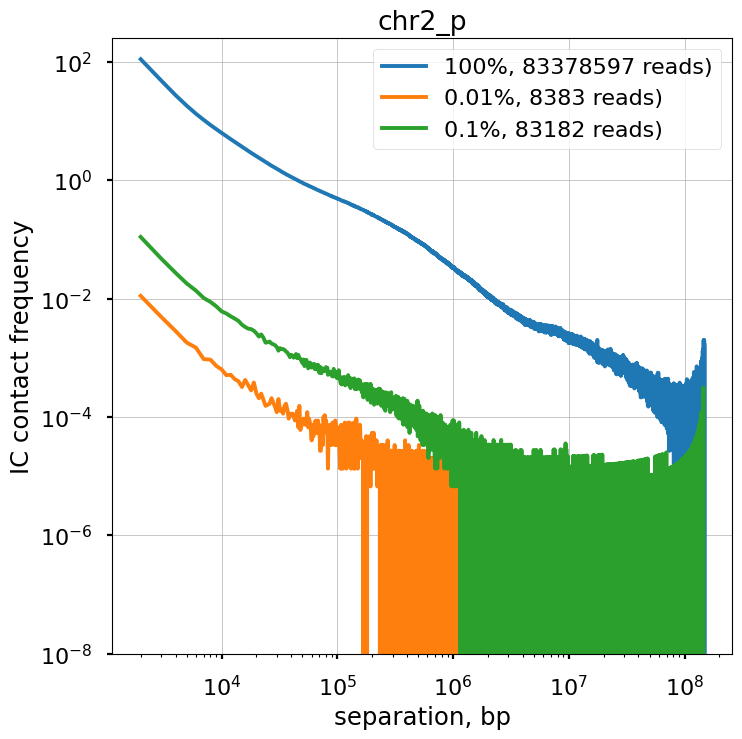
[43]:
# expected calculation for the smoothed data
for frac in downsampling_fracs:
clr_downsampled = cooler.Cooler(f'./data/test_sampled_{frac}_.cool')
cvd_smooth_agg_downsampled = cooltools.expected_cis(
clr=clr_downsampled,
view_df=hg38_arms[1:2],
clr_weight_name=None,
smooth=True,
aggregate_smoothed=True,
nproc=num_cpus
)
cvd_smooth_agg_downsampled['count.avg.smoothed'].loc[cvd_smooth_agg_downsampled['dist'] < 2] = np.nan
cvds_smoothed[frac] = cvd_smooth_agg_downsampled
cvd_merged = cvd_smooth_agg_downsampled.drop_duplicates(subset=['dist'])[['dist_bp', 'count.avg.smoothed.agg']]
der = np.gradient(np.log(cvd_merged['count.avg.smoothed.agg']),
np.log(cvd_merged['dist_bp']))
derivs_smoothed[frac] = der
INFO:root:creating a Pool of 10 workers
INFO:root:creating a Pool of 10 workers
[47]:
f, ax = plt.subplots(1,1,figsize=(8, 8))
for frac in [1]+downsampling_fracs:
cvd_smooth_agg_downsampled = cvds_smoothed[frac]
cvd_smooth_agg_downsampled['count.avg.smoothed'].loc[cvd_smooth_agg_downsampled['dist'] < 2] = np.nan
ax.loglog(
cvd_smooth_agg_downsampled['dist_bp'],
cvd_smooth_agg_downsampled['count.avg.smoothed'],
label=f'{frac*100}%, {num_reads[frac]} reads')
ax.set(
xlabel='separation, bp',
ylabel='contact frequency')
ax.grid(lw=0.5)
ax.title.set_text(region)
ax.legend()
ax.set_ylim(ymin=10**(-8))
f.show()
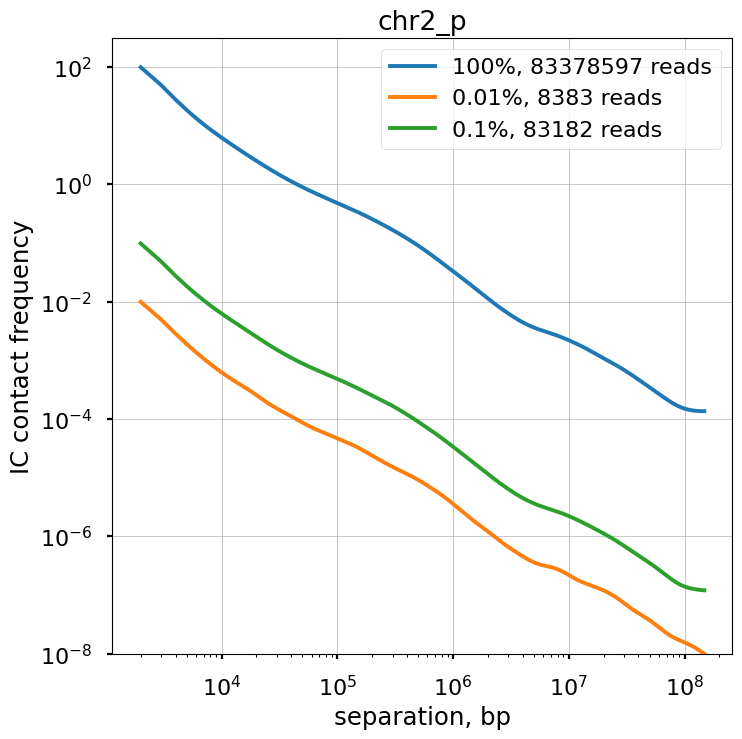
[56]:
f, ax = plt.subplots(1,1,figsize=(8,3))
for frac in [1]+downsampling_fracs:
der = derivs_smoothed[frac]
der[3] = np.nan
ax.semilogx(
cvd_smooth_agg_downsampled['dist_bp'],
der,
label=f'{frac*100}%, {num_reads[frac]} reads'
)
ax.set(
xlabel='separation, bp',
ylabel='slope')
ax.grid(lw=0.5)
ax.title.set_text(region)
ax.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.ylim(-2.25,.25)
f.show()
This page was generated with nbsphinx from /home/docs/checkouts/readthedocs.org/user_builds/cooltools/checkouts/latest/docs/notebooks/contacts_vs_distance.ipynb